Finding a Place for Humans in an AI Future
Also, launching some stuff

One critique I have of LLMs as a tool is that we don't understand how they work. There is a surface-level complaint here that many people working in this space seem to dismiss, but there is also a deeper and less obvious problem that results from this.
Let’s say we want to build software that augments the human ability to understand complex things.
If we want to understand a problem like "understandability", we can take the simple, brute force approach of "just use an LLM bro", or we alternatively can try to actually develop a theory of how understanding itself works, which would likely give us more powerful and less obvious tools, allowing us to do an even better job. If we set our standards at simply having an LLM explain something to us in plain English, we might miss some deeper and more powerful possibilities.
Human imagination is far more limited than we often pretend it is. The world outside your skull is infinitely more complex than the model of it inside your skull. If you aren’t mining the world for newer, deeper inspiration, you will fail to imagine cars, planes, and rockets as opposed to simply faster horses.
If people are going to worry about LLMs replacing humans, then perhaps our response should be to start thinking more deeply about how to push humans to their limits.
If we make the classical comparison and claim that the human brain is a type of computer, one natural direction to go in is asking about the software it runs. There certainly are some substantial differences between ordinary code and things like culture and memes, but there are also substantial differences between a C program and the weights of a deep neural network, and we really don’t seem to have a difference accepting that they’re both software. There are different, alien modes of software out there that have yet to be discovered, computer science is less than a century old and the Library of Babel of code is unfathomably vast, even if we limit ourselves to fairly short program lengths.
Neural software seems to rely a lot more on mimicry - the way humans and animals download and share it is by observing others and copying their behaviors. Humans have the additional method of language, where we can associate abstract symbols and sounds with objects, actions, and other things in the world. We can describe causality chains through stories and explanations, and we can transfer knowledge to others, including abstract and internal states that would otherwise not be apparent purely from the visible behavior alone.

The format of “human software” also changes substantially over time. One notable example is that pre-literate societies often placed an enormous focus on memorization. Music and poetry were often far larger parts of daily life, as a bit of rhythm and rhyme introduce a lot of repetitive and redundant structure that make things easier to memorize perfectly.
It’s worth remembering that Homer’s Iliad and Odyssey were composed in the 700s BC, during the Greek Dark Age, some three or four centuries before Greece regained writing. These are absolutely gargantuan texts (the two combined are almost half the length of the Bible), and were passed down entirely by memory for centuries. They also include a number of details about the Trojan War and the Bronze Age Collapse, albeit heavily fictionalized.
The Iliad also notoriously includes the Catalogue of Ships, a chapter which autistically lists off a ton of statistics about the entire Trojan-War-era Greek Navy, and perhaps was partially a way of allowing bards to show off their impressive memorization abilities. The Method of Loci, a memorization technique based on constructing a mental space to navigate full of meaningful reminders, also traces back to ancient times.
Things that were completely mundane and ordinary to such pre-literate societies may seem like unbelievable superhuman mental feats today. It’s worth considering what other feats the brain is capable of if pushed in the right direction.
There are a variety of numbers that people throw around about the computing power of the human brain, though they often heavily simplify the neuroscience and most probably underestimate the brain by a fair bit. Nevertheless, the numbers are usually enormous - usually peta- or exa-scale compute, and tens or hundreds of petabytes of storage. Given the "human software” angle we’ve been taking, there are many different ways of writing programs to get the same job done, but some are vastly more efficient than others. Is the code we’re running on our brains closer to heavily-optimized “Neural C”, or is it a really poor Python implementation? Various divisions of cognition (rational versus intuitive thinking, for example) may be analogous to wildly different programming paradigms, though perhaps we should be skeptical that these are all that is possible. As we understand the brain better, we can likely push things in a more optimized direction.
So if we want to push humans closer to their true limits, perhaps as a way of maintaining relevance against AI for longer, perhaps as a way of better understanding our own minds, perhaps as a way of exploring what brains are truly and unexpectedly capable of, perhaps in pursuit of a form of “cognitive innovation”, we need some place to start. A good place to start may be in finding some cognitive thing that we have some basic intuitive sense of, and digging a bit more deeply into it, with the eventual goal being to build tools to augment and accelerate it.
Back to understandability. This is a fairly abstract problem, but I’d like to highlight a few observations about it:
Understanding is rooted in familiarity. Humans have certain motifs they follow for building stuff, and the inverse of that (pattern matching) is a key part of how we interpret new things.
More components, especially redundant components, can often increase the "surface area" of something. If you can see the same thing from multiple perspectives, the odds that you'll recognize a familiar fragment to latch onto to help you "get it" improve. Understanding of one component can often narrow possibilities enough to help understand connected components.
This works in the opposite direction too; heavily optimized code (superoptimized code especially) often will prioritize unfamiliar shortcuts over staying within a more limited toolset of familiar patterns. Human familiarity is a constraint that limits options, and if you optimize for something unrelated, you'll end up with something difficult to understand.
If you can see a large number of moving parts and the order behind the chaos (visualization often does this), that often can help too, though some perspectives will make relevant order more or less legible.
Many things like code and theorems have large equivalence classes; there are a large number of ways to rephrase them that are all equivalent, but where the precise details of how they work may be very different. There are dozens of known ways of proving the Pythagorean theorem, there are dozens of ways of reframing Euclid's Parallel Postulate. There is nothing special about these particular theorems that give them so many equivalent perspectives; they are simply problems that have gotten a lot of attention for a very long time, and so many alternative perspectives on them have been found. If we threw enough mathematicians at the problem, we could in time have a hundred very different proofs of a much harder problem such as Fermat's Last Theorem, each of which may provide a completely different perspective on why it is true that may highlight new connections in mathematics, and may make more or less sense to different people.
Of course, we also want to expand human familiarity. What is and isn't a familiar technique may vary substantially from person to person, especially when dealing with more niche methods. There also needs to be effort put into not merely reframing things into familiar terms, but in making the unfamiliar familiar whenever it makes sense to.
Astrolabe and The American Compute Company
I’ve been thinking for many years at this point about how to improve the efficiency of modern CPUs. The way we design modern CPUs generally says a lot more about historical accidents, half-century-old technical constraints, and primitive early human concepts of computing than it does anything more fundamental or physically constrained. Modern CPUs spend enormous amounts of resources attempting to extract miniscule amounts of parallelism from sequential chains of instructions and waste huge amounts of energy throwing very crude heuristics at managing the physical layout of data.
A few months ago I got around to incorporating this project as The American Compute Company. Designing a completely new ISA from scratch with a number of unique ideas around data layout and semi-static scheduling is an ambitious problem. This necessarily throws away a great deal of software compatibility, and in a way that efficient emulation may be tricky. I’ve seen other companies build very impressive hardware and then fail because of poor programmability and a lack of software support, and I am not interested in making the same mistake.
My approach in developing this chip is to put a large focus on software. I need usable and useful software to ship with the hardware on Day 1. It makes sense to build the software and hardware in tandem. The final hardware may be very alien compared to traditional CPUs, but it’s necessary to also make sure it does not become so alien as to be unusable. Good and innovative development tooling can help make up for some of this, but software should absolutely not be an afterthought. Furthermore, with the aim of pushing the efficiency of hardware, it makes sense to have real software to optimize the hardware around to make sure that features in the hardware, especially experimental features, properly reflect behavior of actual code.
This software-heavy focus also has some other advantages. It lets me try out some experimental ideas (I have a number of ideas around development tooling), and some of this code can also be run on existing hardware in the meantime and can be sold to bring in some revenue to fund chip development.
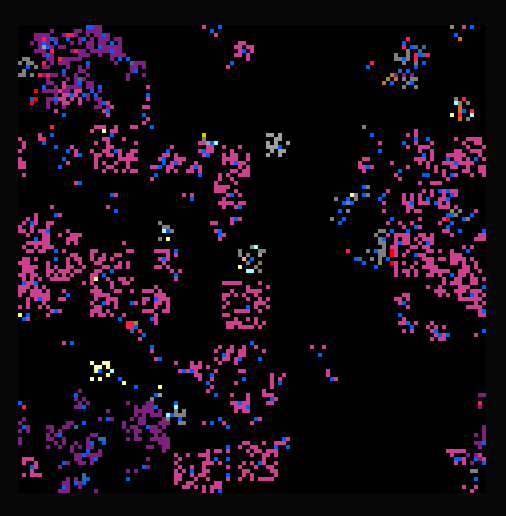
A few days ago I released Astrolabe, an interactive codebase visualization and mapping tool that I built. It’s fairly experimental at the moment and there are plenty of additional features and polish I’d like to add in the future to make it more useful, but at the moment it’s fun to mess around with, generates some eye-catching visualizations, and get some basic intuition for big codebases.
In the age of AI, we should be aiming to build tools that advance human intuition and understanding of complex systems.
It’s currently fairly language agnostic and isn’t extremely sensitive to code structure beyond the identifiers it parses out, but it supports a decent number of languages. I have some ideas on text embeddings and approximate parsing methods I’d like to try out in future versions to hopefully make it a bit more useful. It supports a couple dozen common languages, so it should work with anything from Haskell to Javascript to C to Verilog.
Astrolabe is currently priced at $25 and can be found on the American Compute Company website for those who want to support the project and mess around with something a bit more fun than piping grep and awk together to locate stuff. I have some other software projects in the pipeline as well, which will be announced as I make progress on them.


It’s been a few months since the last article, I’ve spent a lot of time coding lately, though I’d like to get back to writing frequently and have a number of vert intersting articles in the works.