The Lattice-Topology Correspondence
An Odd Coincidence Suggests a New Path For Computing

I've talked before about the potential for making theoretical computer science more closely resemble geometry. Here, I'd like to deliver on that with some actual motivating examples.
I’d like to start by pointing out an odd mathematical coincidence, then move into sketching out an intuition for the two different sides of this coincedence. This won’t be overly technical, I can save that for future writing.
Lattices and Topologies
In mathematics, there is a type of structure called a Lattice. Or actually, there are really two types of structures in mathematics called lattices, but I’m referring specifically to the kind found in order theory.
A Lattice (L,≤) is a partially ordered set with the following properties:
There exists a single maximal and a single minimal point in L.
For any two points in L, there exists a common maximum of both points.
For any two points in L, there exists a common minimum of both points.
Lattices are a very common mathematical structure in discrete math, and as we’ll see later are very useful for modeling abstract computation.
Topology is a branch of mathematics that models spaces in a way that highlights little more than their continuity. Things like volume, distance, angles, etc. are abstracted away, while properties like the number of connected components and the number of holes are preserved.
Another way of thinking of topology is as something very close to the bottom of the geometry stack; most familiar geometric spaces are just topological spaces with some additional structure layered on top.
There are several ways to define a topological space, but I’ll use the version based on open sets here:
A topological space T is a family of subsets (open sets) of a set X such that:
Both X and the empty set are included in T.
Any arbitrary union of elements of T is also in T.
Any arbitrary intersection of a finite number of elements of T is also in T.
Reading these two definitions, it doesn’t take much to notice that these two definitions are very similar. For most intents and purposes, the real difference between these two mathematical structures is namely that the definition for Lattices is generally optimized for problems relating to discrete, often finite sets, while the definition of a Topological space is generally optimized for problems relating to continuous, often infinite sets.
An intuition that can be used for thinking about these structures is that they define something that behaves similarly to space by providing a number of individual pieces of space and defining union and intersection operations on them. Talking about regions of space being composed of smaller regions of space that have been stuck together.
The particular detail about only allowing finite intersections in a topological space is specified to avoid certain situations involving infinite sequences isolating individual limit points; topology, focused on continuous spaces, generally is meant to talk about regions of points that are near each other rather than individual points.
Some Intuition for Topological Computation
One thing worth pointing out before diving into the next section is that this topological/geometric viewpoint of computation doesn’t so much focus on computation or operations as it does the structure of data. That said, computation leaves a distinct imprint on such data, and so studying the geometry/topology involved can still us a great deal about the computation indirectly.
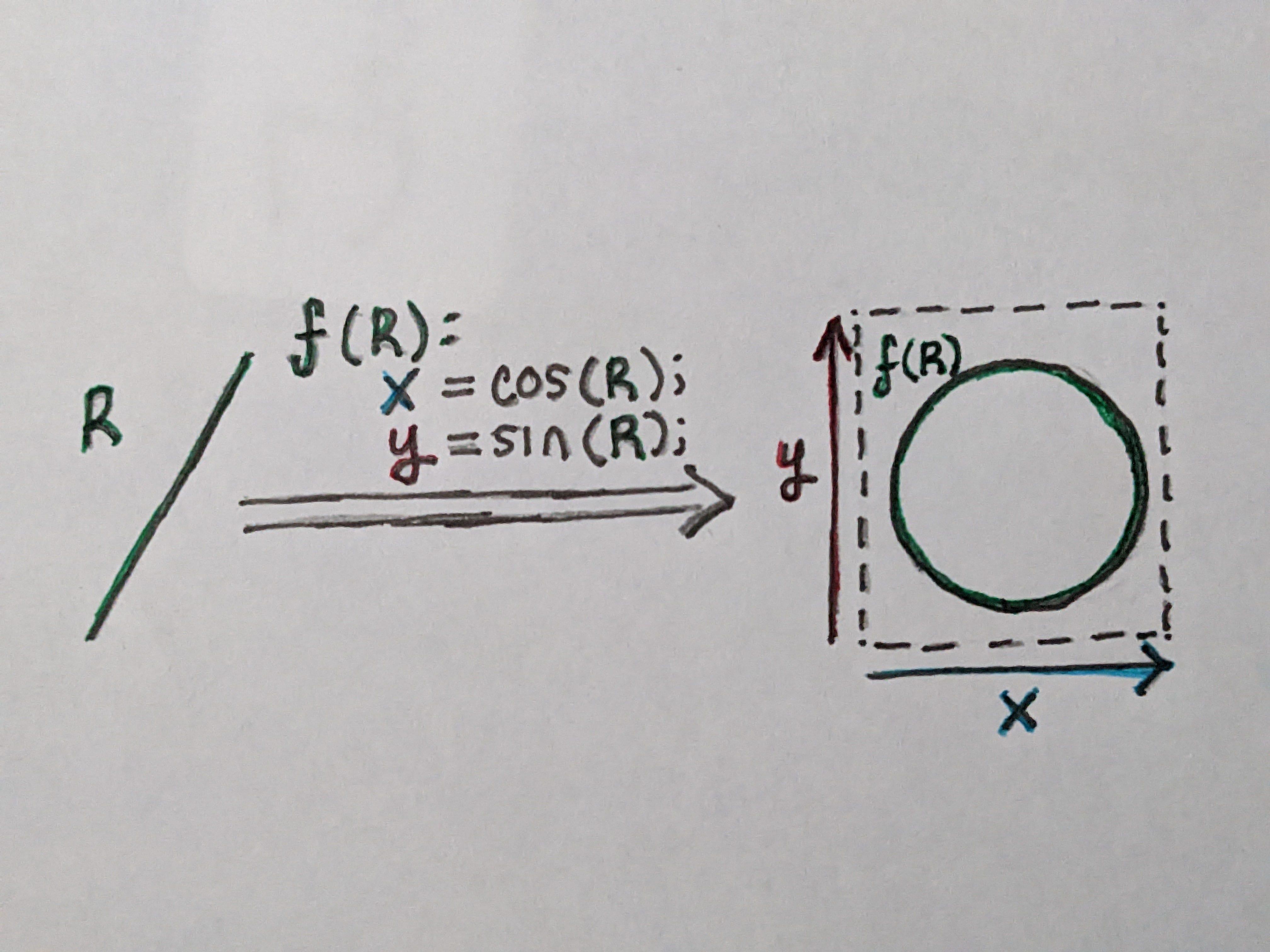
We can start by thinking of a single variable geometrically. Assuming for now that this variable is a number, this forms a single degree of freedom, and its value is a point on a line.
If we introduce a second variable, let’s call these two variables X and Y, the space of possible states happens to form a 2D plane; all possible states of this program are embedded in this plane.
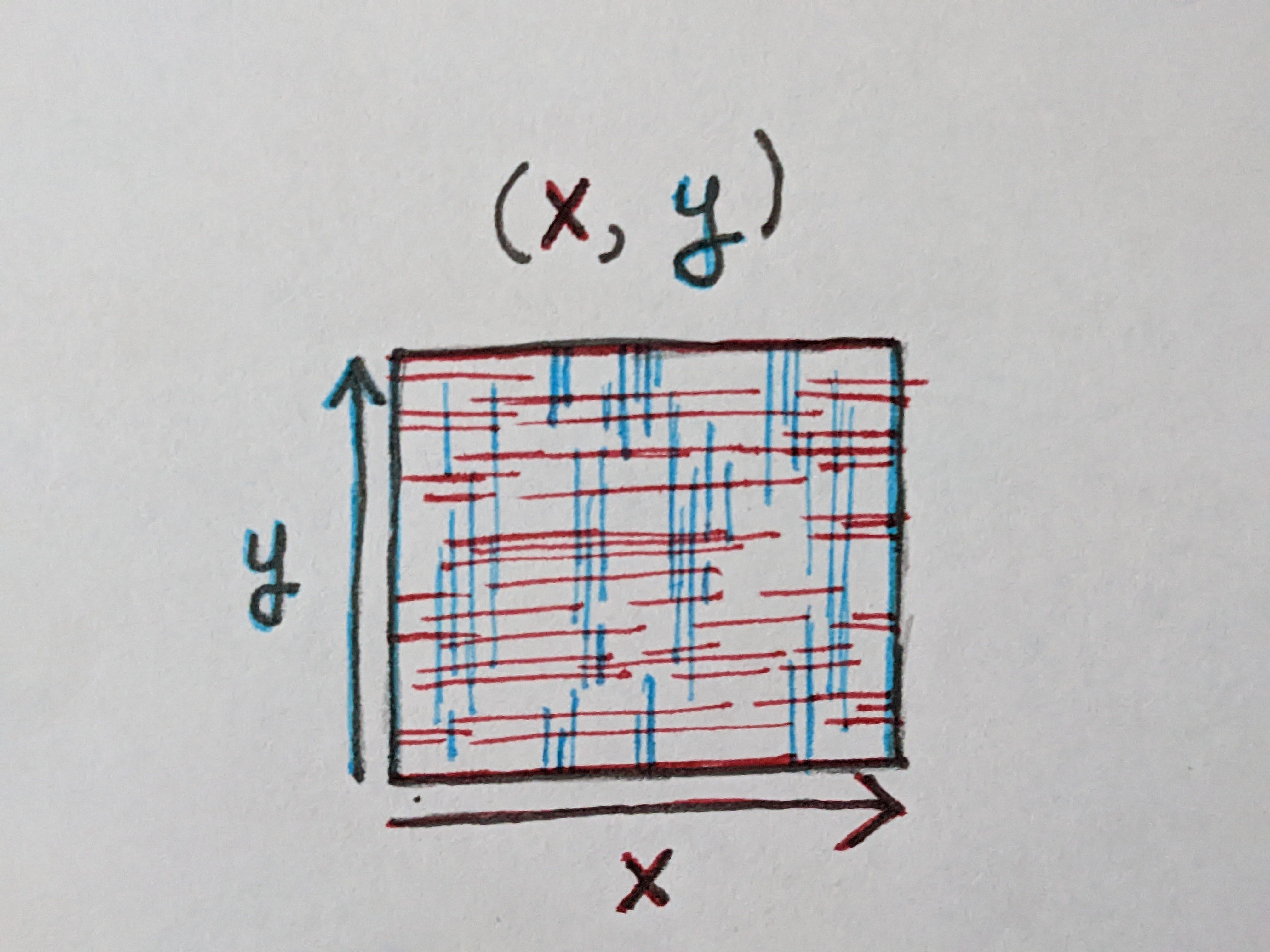
In practice, not every value will be a number, and even those that are might not be best represented by a straight line. I’m not sure it’s entirely clear how continuity or proximity naturally arise in this model of computation, but we can at least find some intuitive examples where the answer is pretty obvious.
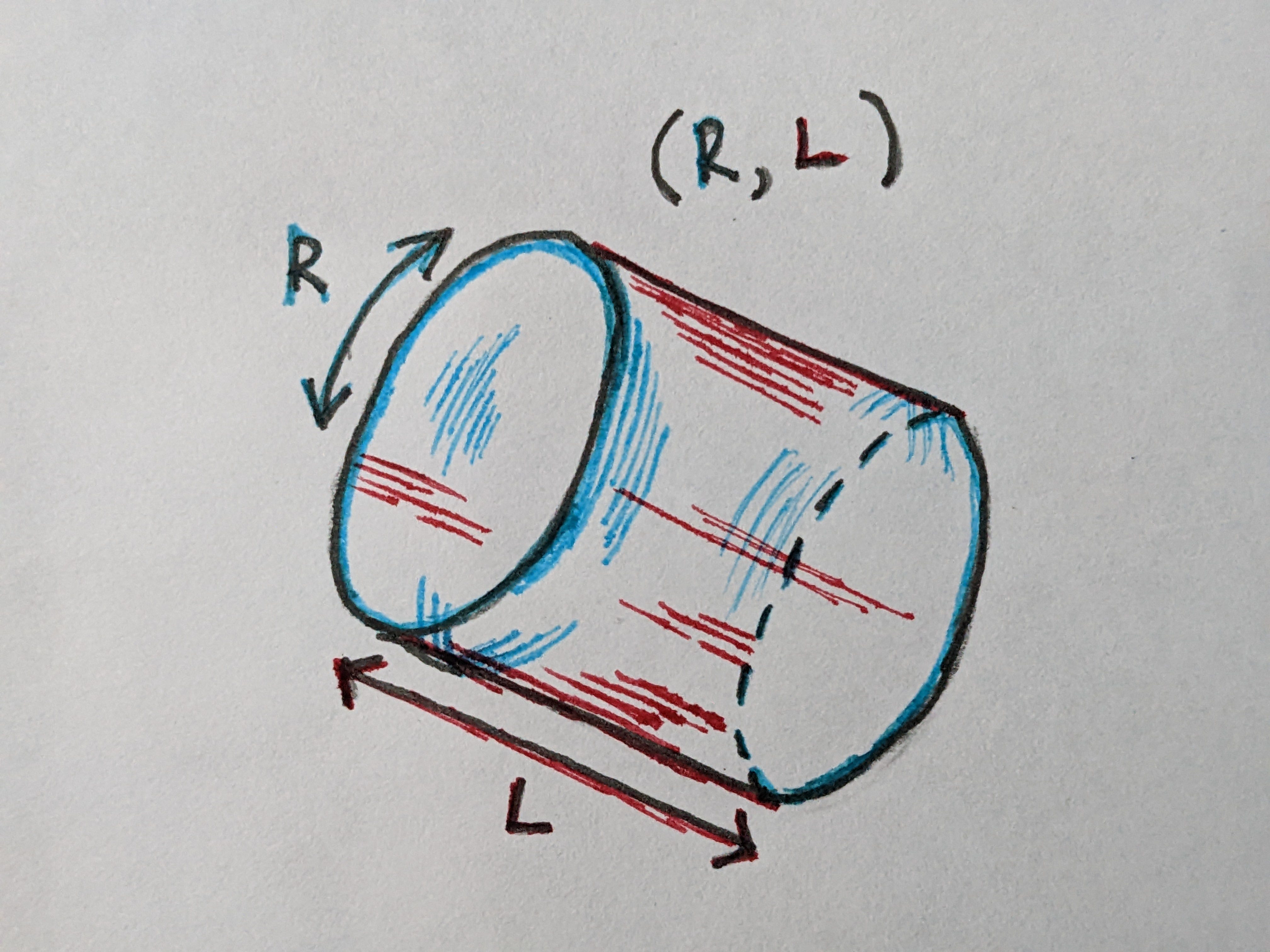
For example, there are some cases where a value may loop around back to the beginning, and so in a sense the beginning and the end are adjacent, forming a circle. This can create more complex spaces; for example a circle combined with a line creates a cylinder.
Some programming languages feature Algebraic Data Types. Granted, even those that don’t have such data types often still have some mechanisms for providing similar functionality, but the way in which ADTs describe “product” and “sum” types provides a nice intuition here.
A product type, equivalent to a struct in more C-style languages, is a grouping of several values. This behaves in the same way as the examples we’ve described above. The number of unique locations in this space (akin to area/volume) is, at a maximum, the product of all the number of states in each field.
A sum type, equivalent to a tagged union, is a way of allowing one of several different types of values to exist. For example, the sum type in the drawing below can either store a 2D (x, y) product type, or a single z variable, but not both at the same time.
The number of possible states of this type (once again, think area/volume) is the sum of the number of states of each of these subcomponents. We can think of these spaces untuitively as joining these two spaces into one, and the bit-level encoding of our data type is a binary encoding of some coordinate on this shape we’ve created.
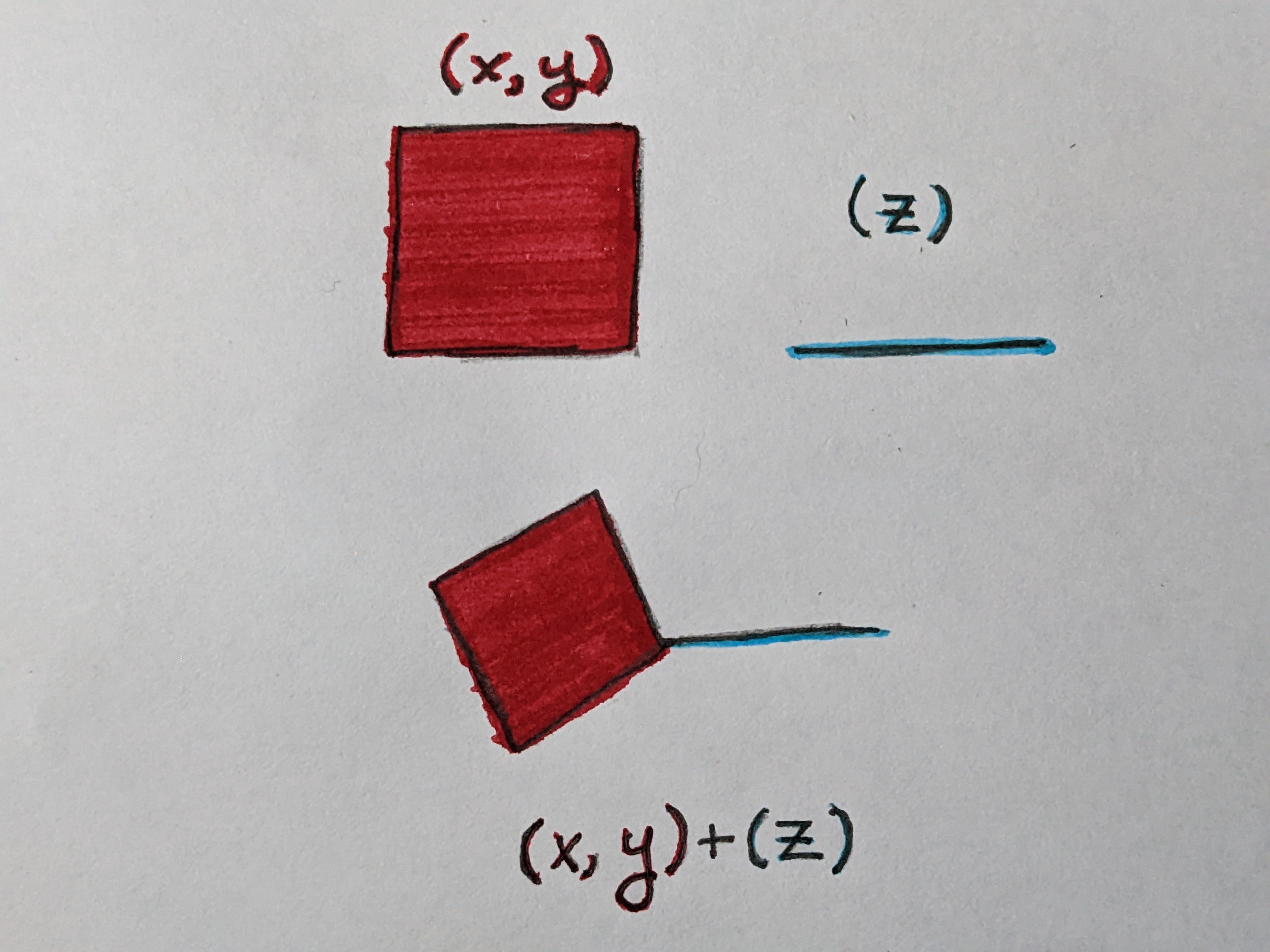
Whenever a computation is performed, there is often some impact on the output. Some values become unreachable. If we for example are given a pair of values (x,y) and apply a function that switches them if x > y, then there are no possible outputs where x > y. We can be certain that after this computation, all possible outputs satisfy the condition that x ≤ y.
This has the effect of turning our square into a triangle.
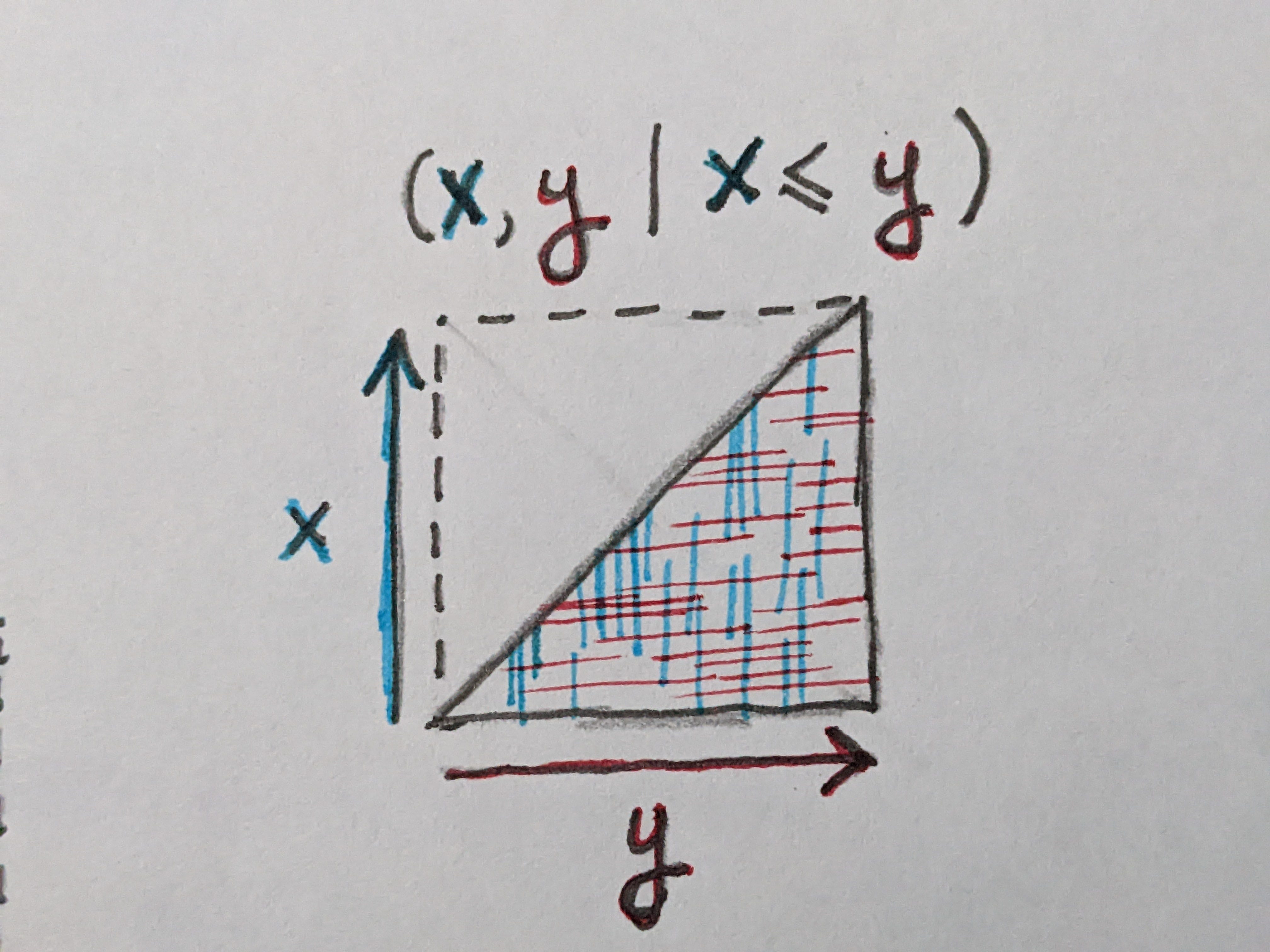
Other computations can constrain the space in different ways. For any arbitrary subset of a number line we would like to include/exclude, we could devise some piece of code that produces such an output space, even if it’s just a giant chain of if/else and return statements.
Given two variables with only certain accessible subsets, the maximum proportion of accessible combinations of those two values is once again their product, though this is often a much smaller subspace, as shown in the figure below. Reachable values of Y are yellow, reachable values of X are light green, but the only reachable values for their product space is the dark green regions.
In practice though, it may be much less than that. After all, in the previous example, for any value of X we can find some value for (X, Y) that contains it. The same can be said for any value of Y that we pick. Yet regardless, there is a more complex relationship between X and Y such that not every possible combination of X and Y is reachable.

It’s also certainly possible for the dimensionality to increase or decrease when a function is applied. If the dimensionality increases, there is often only a very small reachable subspace, whereas projecting from a larger space to a smaller space often has the opposite effect.
These kinds of patterns don’t just arise in simple forms in human code, but also arise in more complex, more natural data. In this case, the data is said to encode a space that embeds a smaller manifold, from which the data is sampled. This manifold is usually a somewhat continuous subspace, though often with a fairly complex, convoluted structure.
A major approach of modern resarch efforts to study of deep learning works is based around viewing the data the neural network is being trained on as lying upon such a manifold, and that the neural network is learning to untangle the manifold to make it easier to draw simple lines that separate categories and clusters.
Similar work has been done in the field of neuroscience too.


Bringing Lattices In
There is a very interesting technique in static analysis called Abstract Interpretation. Abstract Interpretation (AI) is a tool that is very effective at soundly approximating undecidable problems. For example, an Abstract Interpreter can sometimes solve the halting problem. It gets around the impossibility of such a problem by not just being allowed to return true or false to whether a program halts or not, but also has a third option; I don’t know. Returning IDK every time is technically a correct way to approximate such problems, even if it’s not very useful. In practice though, AI is a pretty useful tool and can give the correct answer in a wide range of real-world cases, and the impossibility of solving the halting problem only means that there will always be some cases where the tool has to return IDK, even if rare in practice.
The basic idea behind AI is that there’s a lot of correctness problems that really just reduce to determining if some particular known good/bad state is or is not reachable by a program. Unfortunately, mapping out every individual reachable path through any nontrivial program is hopelessly impractical due to the sheer numbers involved.
The approach taken by Abstract Interpretation is that, rather than represent each individual path through our program, we use more abstract spaces, called Abstract Domains, that represent a much lower-resolution version of our set of possible program states that’s much easier to operate on.
In this case, we’re not representing the actual set of possible paths through programspace directly, but rather we are encoding what is often a much wider range of possibilities and attempting to shrink it down and tighten our bounds to rule out the possibility of the program reaching certain states.
Below is a drawing to provide some intuition. The black arrow line represents the actual path the program takes through programspace. Ideally we want to avoid the ERR, CRASH, and BUG bubbles. The blue, green, and orange bands represent tighter and tighter approximations of the path; the innermost orange path is able to rule out that ERR and BUG are unreachable, but not crash.

One simple example of how this might be done is sign arithmetic; for every integer we could store a set (+,0,-) that tells us whether the value is capable of being positive, negative, zero, or some combination of these. If we have a value that we know can only be zero or positive and multiply it by another value that we know can only be zero or positive, we can infer that the output is also either zero or positive.
This specific case can of course be generalized to more complex domains such as interval arithmetic in order to gain much more precision. Additionally, very different types of domains such as known-bit analysis and certain congruence properties can also be modelled. All of these systems can even be combined and used together for even more precision.
Further, more complex Abstract Domains can be created that work across multiple variables at a time, such as domains that can specify that X > Y, or that (X-Y) > k, or by representing the space of reachable values as some convex polyhedra.
I hope some of this is sounding familiar by now.
Intriguingly, all of these different domains are in fact lattices. For example, over the aforementioned sign domain, the union of (+) and (0) is (+,0). The intersection of (+,-) and (0,-) is (-). The empty set () is representable (though perhaps not often used) and the full set (+,0,-) basically pertains to the situation where the domain is too imprecise to say anything useful about the state of our variable.
Intervals work in a similar way, though it’s worth noting that they can easily lose a lot of precision when given intervals that are far apart. This is because interval arithmetic only stores a minimum possible value and a maximum possible value.
We can see in this diagram below what happens when we combine intervals A and B; the union contains this large region in the middle (colored red) that is contained by neither original interval, but is contained in their union.

Future
I think it’s fascinating that a perspective of data that ends with cutting-edge machine learning and neuroscience research can arrive in a mathematically very similar place to the end result of an attempt to tackle problems that straddle the border of what is and isn’t even mathematically possible to compute.
That there is such an intriguingly close similarity between intuitive, geometric interpretations of data and techniques for talking about the behavior of large numbers of computational trajectories I think suggests that there are some. I suspect we’re just scratching the surface of what is and isn’t possible here and that future tools in this space, both software tools and more abstract mathematical tools, will reveal a much more geometric nature of compuation than what most people currently intuit.
Of course, that assumes that people are building such tools and investigating such mathematics. I personally haven’t heard this particular aspect discussed before. Perhaps no one has before really put 2 and 2 together in this specific way. Hopefully I can raise some awareness of this and attract some more people into this line of thinking.
That said, I personally strongly believe in the philosophy of “the best way to predict the future is to build it”. If no one else builds it, you’ll certainly see some of my progress toward this and similar avenues here in the future.
I’d like to thank everyone for the enormous amount of support I got after the last article unexpectedly blew up on the orange website. I don’t post on there often and I definitely avoid reading comments there - they’re often pretty negative.
I expected my “The Next Century of Computing” article to get around 80-100 views and to net me two or three new subscribers, maybe a paid sub if I was lucky. As of writing, it’s received over 10,000 views, just short of 100 new subscribers, and around 10 new paid subscribers (though a little disappointingly, there have been a lot of paid subs on “free trials” who cancel as soon as they’ve read past the paywall, oh well).
I hope this article and the ones that follow it live up to the hype that I’ve apparently built up. I’m trying to do some big things here, and to build some fantastic new things that I don’t see elsewhere. That necessarily relies on believing unorthodox things, and exploring weird ideas that everyone else overlooks. I’m generally pretty underwhelmed by the state of technology today, the potential I see in it is far greater. I hope I can spread a small fragment of that vision and optimism.
Once again, thank you so much for your support. I’ve been in total shock for much of the past week at my article being nearly 100 times more successful than I expected.