The Most Profound Problem in Mathematics
A problem vastly more important, and vastly more bizarre than most people realize

About 2300 years ago, the Greek mathematician Euclid published his book The Elements, which has since become one of the most influential books in all of mathematics, if not the world. It is estimated to be second to only the Bible in terms of the number of printed editions since the invention of the printing press.
At the foundation of the text is Euclid’s five axioms of geometry, a small set of basic rules (postulates) from which all of Euclidean geometry emerges.
A straight line can be drawn, connecting any two points.
A finite straight line can be extended to any arbitrary length.
A circle can be drawn from any center and radius.
All right angles are equivalent.
If a straight line falling on two other straight lines makes the interior angles on the same side less than two right angles, the two straight lines, if produced indefinitely, meet on that side on which the angles are less than two right angles.
One of these things is clearly not like the others. Very quickly after Euclid first published The Elements, the fifth postulate, also known as the parallel postulate, was criticized for not being self-evident. For two thousand years, many of history’s greatest mathematicians attempted and to either disprove it or derive it from the other four postulates, with no success.
By the early 1800s, mathematicians Gauss and Schweikart had both independently found hints of the truth about the parallel postulate, but both refrained from publishing their work out of fear of how shocking the implications were. However, the study of hyperbolic geometry slowly began to emerge throughout the 1820s and 1830s. In 1854, Bernhard Riemann established the field of Riemannian Geometry, generalizing geometry to spaces that vary in curvature.
Slowly the 2000-year mystery was unraveling, and the implications were bizarre; Euclidean geometry is not the only valid kind of geometry, and that the fifth postulate can be swapped out for alternatives that are equally valid, albeit in different contexts. It is difficult to understate just how counterintuitive and bizarre this was at the time. After all, Carl Friedrich Gauss, often considered one of the greatest, if not the greatest, most respected, and most influential mathematician of all time, himself was afraid to publish such an idea.
In retrospect, this was perhaps not too surprising. The Greeks had extensively studied the geometry of the sphere, and had even dabbled with hyperbolae, the two main types of non-Euclidean geometry. Other mathematicians had over the centuries come close but held too tightly to the idea of a single, universal geometry.

If a line is defined as the shortest path between two points (also called a geodesic), lines in spherical geometry form great circles, and any two great circles either intersect in exactly two points or are equivalent (intersecting at all points). Spherical spaces converge toward a finite volume. In hyperbolic geometry, parallel lines diverge and space grows exponentially with distance.
Riemannian geometry studies complex curved shapes where curvature and the behavior of locally parallel lines varies across the space; some places are flatter, some more curved. In the 1870s, the Erlangen Program was established, providing mathematicians a common goal and framework by which they could revolutionize geometry with the strange, powerful new tools that the solution to this 2000-year-old problem had provided. In 1905, a German patent clerk began publishing works connecting then-unsolved problems in physics with Riemannian Geometry, laying the foundations of modern physics and all the things in our modern world that its study has enabled.
Euclid’s fifth postulate has been one of the most bizarre problems in the history of mathematics. By trying to distill mathematics and geometry down to its most pure and rigorous principles, Euclid accidentally revealed limitations of the human reasoning of the time. Upon solving them, a vastly deeper understanding of the world was unlocked. It’s hard to argue that an enormous amount of our modern world is not directly due to the consequences of this solution.
Believe it or not though, there is another problem in modern mathematics that seems to closely resemble it. A problem currently unsolved, lying extremely close to the most fundamental mechanics of all of mathematics, logic, and computation, and a problem that has been showing symptoms very similar to those that the fifth postulate showed that hinted at its profundity and bizarre solution.
For a more in-depth explanation of non-euclidean geometries, in particular hyperbolic geometry, this video is a good introduction:
P vs NP
The million-dollar prize available for a solution to P vs NP does not do the problem justice, nor would a billion-dollar prize, or even a trillion-dollar prize.
A common misconception about P vs NP is that its consequences merely extend to cryptography and no further. The nature of the NP complexity class in fact goes far deeper, down to some of the most basic properties of mathematics itself. It is to a large extent a question about the very nature of chaos, luck, and intelligence.
The common statement of the problem is that there are two complexity classes involved; P and NP, and we are asking if they are or are not equivalent.
P stands for Polynomial time, and is the class of all problems that can be solved by a polynomial-time algorithm running on a classical computer.
NP stands for Nondeterministic Polynomial time, which is a really terrible name. The “nondeterminism” here is a very different idea compared to the much more well-known concept of “nondeterminism” from physics. Nondeterminism in computer science is an imaginary capability of a computer that allows it to try out every solution to a problem at once while only paying the cost of one try.
For example, it would be useful if we could take a digital circuit or a computer program, scan across every valid state it could ever be in, and check if any of them produce any unwanted behavior. If we have an efficient way of checking if an individual state contains bad behavior, and if the number of possible states is finite, this problem is in NP.
Another, arguably much more profound case, is to imagine a fixed-length text file where we could store a mathematical proof. For any given problem in mathematics, no matter how hard, we could ask a nondeterministic computer to scan through the Library of Babel and quickly give us a file with a correct proof or disproof of the problem, if one exists. Once we have said file, verifying it is merely a matter of reading each statement of the proof and checking that it follows from the last, which is roughly linear time.
Note that this doesn’t let us solve undecidable problems, or refute Gödel’s Incompleteness theorems, but it comes pretty close. Turing and Gödel proved that there exist programs with infinite numbers of reachable states and mathematical proofs of infinite size. Given a finite possibility space that our nondeterministic computer can search through, infinite problems (or even just really big problems) are out of reach.
But most stuff we care about is not infinitely hard, and so a nondeterministic computer could theoretically automate a lot of this work for us, if we could create one.
An equivalence between P and NP would imply the existence of some algorithm that could augment any verification algorithm in P (the algorithm we use to check if a solution is valid) and reduce the cost of trying every possible solution at once to only a polynomial-time slowdown factor rather than the exponential-time one that would normally come from checking every possible solution.
A problem key in determining the difficulty of logical reasoning and in telling us whether some of the hardest problems in all of mathematics are actually hard at all, or if we've fundamentally been doing math and reasoning the wrong way this whole time is obviously a profoundly important one. Not just for math, but for any kind of logical reasoning as well. Basically everything we use our brains for.
P = NP : Societal Vacuum Decay
One way of viewing the P vs NP problem is as a study of the limits of luck; to what extent can you algorithmically generate your own luck to improve the outcomes of a problem, and to what extent must you rely on random chance and brute force? A proof that P=NP would for a vast range of cases turn the answer to “not at all”. To a large degree, we’re able to work around luck with intelligence, though as we will see later, our amazing intellectual capabilities are no evidence that P=NP.
One particularly scary scenario I’d like to highlight though is that all of human society, not just our digital technology, has a strong cryptographic component. After all, language is an information technology, and we need ways of figuring out who to trust and who is lying. One way to combat lying from a cryptographic perspective is with interactive proofs - asking questions and looking for inconsistencies in the answers, not too unlike the natural human tendency to question suspicious people.
Imagine a world where there is an easy way to figure out exactly what to say to someone to trick them into believing anything you say.
A world where P=NP would be a truly alien one, and the discovery of such an algorithm in a world full of P!=NP-adapted brains, instincts, and social norms could be best compared to a societal vacuum decay.
P != NP : An Enlightened Struggle
What of a world where P is proven distinct from NP?
This is a world where many hard computational problems that we face today would remain hard. At the very least, it would be a world where we’d be no worse off than we are now.
However, as we will see later, there are an enormous number of bizarre properties of NP problems. Solving them in practice is often much easier than solving them in theory, and the vast gap between theory and practice hints at something bizarre going on.
Right now, we see strong indications that there is a logic underlying which NP problems are truly hopelessly hard and which are actually tractable, however we currently have very little of an idea of what this logic is.
Furhter, it’s clear that the techniques we’re using to solve problems are far from optimal. Every wrong guess when solving an NP problem is information that can be used to make a better guess next time, and there is continual improvement and optimization in the field of algorithms for making these decisions.
A world where we know the true nature of these problems is one where humanity has a vastly more detailed map of what we are and are not capable of. We can better understand what problems can and cannot be computed. We can better understand what actions can and cannot be coordinated. We can better understand what knowledge can and cannot be derived.
We may still have to struggle with hard problems, but we will gain the tools by which we can become much wiser in how we approach them, how we solve them, and how we know when a problem simply isn’t worth the effort.
Understanding NP : the Sudoku Analogy
Let’s actually start out with Sudoku, as it turns out to be a pretty good introduction to not just the structure of NP problems, but also in understanding the strange behavior they exhibit when we attempt to efficiently solve them.

In Sudoku, we are given a 9x9 grid with some numbers filled into some of the cells, like the one above. We also have a set of constraints, namely that every row, every column, and all 9 3x3 blocks that make up the grid must contain all numbers 1 through 9. To find the solution to a Sudoku puzzle, we must fill in all the empty squares such that these constraints are satisfied.
For example, the above problem features a 5 in the center cell. This means that no other cells in the center row, the center column, or the center block can contain a 5 either, as having repeats of a number would require us to leave out one of the 9 digits.

One thing we can do is, for every known variable and every constraint it interacts with, we can propagate this information out across the grid, allowing us to construct a superposition of the possible states of each cell. For example, the highlighted cell here has a superposition of [6, 7, 8] because [2, 5] are already used within its block, [1, 2, 3, 4] are already used within its row, and [1, 4, 5, 9] are already used within its column. The only remaining possibilities for this cell are thus [6, 7, 8].

Several of the cells in this puzzle have a superposition of just one value, and so as there is only one possible state we are able to collapse that superposition. This can often cause inference cascades that collapse several other cells as well, usually starting with neighboring cells that only have 2 possible states, one of which we just eliminated. Eventually though, the cascade comes to and end and we must resort to guessing.
If we guess wrong, we will eventually reach a contradiction, resulting in a cell with zero possible states. In this situation, we must backtrack and change one of the previous guesses we made.
Another thing that can happen is that distant cells can become correlated or entangled. If two cells in a common row, column, or block find themselves with a superposition of [1, 7] for example, there may be uncertainty about which one is 1 and which is 7, but it’s clear that if one is 1, the other must be 7, and vice-versa.
Entanglement is in a sense just a more general form of superposition, one that applies across multiple cells. A single cell can be in one of nine possible states, whereas a pair of cells together have 81 possibilities. This grows exponentially as we add more cells, and accurately encoding the set of all possible entanglements in a Sudoku puzzle requires a superposition of roughly 9^(9*9) possible states.
In a sense, everything in the puzzle is one giant entanglement, with simple pairs of highly-correlated cells just being the easiest case to reason about. The common case across the entire problem in weak entanglement across larger numbers of cells.
The reason why I’m using terms here from Quantum Mechanics is because the math behind these two fields, while not exactly the same, is remarkably similar! If we view the NP version of superpositions as a vector of boolean values (for each cell there are 9 true or false values, each one determining if its corresponding digit is allowed there or not), the quantum version simply uses probability amplitudes instead, and requires that all amplitudes add up to a probability of 1.
It’s definitely more complex than this, but you can go a long way in understanding quantum mechanics as just a probabilistic variation on NP problems with a few other conservation laws mixed in.
SAT
If you’re willing to generalize Sudoku to arbitrarily large puzzles (beyond the 9x9 grid), Sudoku becomes NP-complete, meaning that any other problem in NP can be converted into such a Sudoku puzzle in polynomial time. If you find a solution to that puzzle, you can then convert its solution back to a solution to the original problem in polynomial time.
There are a large number of different NP-complete problems, including SAT, the Traveling Salesman Problem, the Subset-Sum problem, Graph Coloring, and many more. These are in a sense all equivalent to each other in terms of expressiveness, in a similar way to how all Turing-complete systems are equivalent to each other. Keep in mind of course that Turing tarpits are a thing.
Let’s focus on SAT a bit. SAT, or the Boolean Satisfiability Problem, is arguably the best-studied NP-complete problem. A thorough explanation of it can be saved for another time, but the simple explanation of it is that it’s a bit like a generalization of Sudoku. Instead of a grid, we have a mere collection of boolean variables. The rows, columns, and blocks are replaced with arbitrary constraints that take forms like (+1 -2 -3), which is the equivalent of the expression (x1 or (not x2) or (not x3)). These constraints can involve any arbitrary subset of our variables. A valid solution is a combination of true and false values we can assign to these variables such that every constraint returns true.
It turns out that there is then a very simple way we can transform digital circuits into SAT problems, that being the use of Tseytin Transforms. We simply represent every wire, input, and output in a digital circuit as a variable, and every gate as a collection of constraints between the wires it connects to.
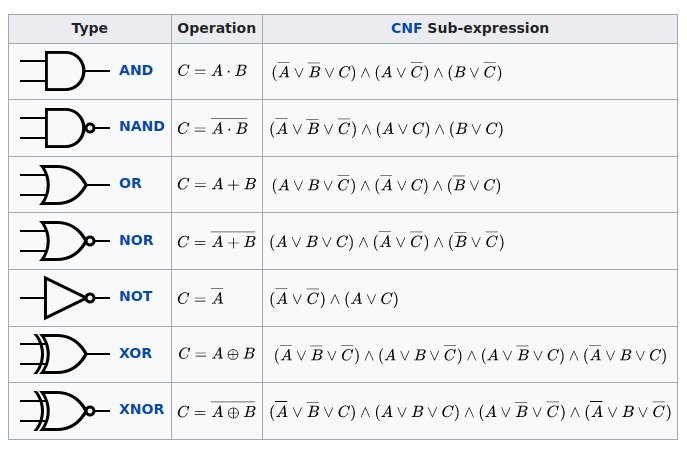
If we apply our intuition about Sudoku puzzles to this, we get interesting properties. Every variable, every wire is fair game to start guessing on, or to start propagating through. We don’t need to start at the inputs, and in many NP problems we might not have access to the inputs. After all, the inputs determine the exact state the system will be in, and we’re scanning across all possible states.
Maybe though we know what outputs we’re looking for, in which case, NP gets a peculiar interpretation.
If P is roughly the class of problems we can represent with a finite number of logic gates that run forward in time, computing outputs from their inputs, NP is a class of problems where we are given much more freedom.
For example, an NP problem that searches for values of x such that f(x)=0 is equivalent to running f in reverse, computing f’(0)=x. The circuit we use to represent the inverse of f is the same as that we use to represent f, we just run the logic gates backwards.
We don’t even need an NP circuit to flow in a single direction; the outputs of a circuit can feed back in as its own inputs if we so choose. We can link any output of any gate to any input of any other.

If we know all of the inputs to a logic gate, we can propagate that forward in much the same way that we propagate the consequences of specific values through constraints in a Sudoku puzzle to collapse the superpositions of other variables. We can always derive the outputs of a gate given all its inputs.
If we know the output of a gate though, we can sometimes derive its inputs. If the output of an AND gate is 1, we know that both inputs must be 1. If the output of an OR gate is 0, we know that both inputs must be 0. Et cetera.
SAT Solvers
There are programs that do this called SAT solvers. You can give them a file describing a set of constraints across a number of variables, and they can intelligently search through the space of all possible states using very similar tactics to a human solving a Sudoku puzzle. There are often a variety of other techniques and heuristics layered on top, but SAT solvers can be remarkably fast!
There are some problems where brute force would take unfathomably long periods of time to solve that a SAT solver can solve in merely a few minutes. On the other hand, there are other problems with only a few hundred variables that might take a SAT solver eons to solve.
The peculiar thing is that modern complexity theory really has no way of explaining this. The best we can say is that “real world problems” tend to be easier, but so far no one has come up with a definition of “real world problems” that doesn’t have hard counter-examples.
There are some hints - for example, we can visualize SAT problems as a graph where variables are nodes and constraints are edges. Hard problems tend to resolve giant hairballs, whereas “easy” problems tend to be a web of small hairballs.

One old and long-standing observation in Complexity Theory research that has been made is that cryptography and machine learning appear to be opposite fields. Hardness proofs in cryptography often can be directly translated into easiness proofs in machine learning, and vice-versa.
The goal of cryptography, after all, is to obscure information with complex systems. The goal of machine learning on the other hand is to extract information from complex systems. In a sense, SAT solvers are like an exotic form of the latter, efficiently extracting solutions from complex systems.
The most substantial improvement in practical SAT solving came from the creation of CDCL SAT solvers; SAT solvers that record information on wrong paths that have been taken in order to avoid making the same mistakes in the future. Learning, in other words. Some recent research has even directly applied machine learning to solving SAT.
Yet another way in which NP is deeply connected to the nature of intelligence.
For a more in-depth explanation of SAT solvers, this talk is a good introduction:
Barriers
While very little is known about how to solve the P vs NP problem, we have a much better idea of how not to solve it.
The problem has spent the past few decades going through a peculiar cycle:
Mathematicians find some amazing new technique for solving other problems in complexity theory.
They successfully apply this technique to a wide range of problems, but are not successful in applying it to the P vs NP problem.
Eventually, someone comes along with a proof that this technique is fundamentally incapable of making progress on P vs NP.
Repeat.
This process has so far happened three times, producing three known barriers to solving the problem.
The Relativization Barrier was first proven by the Baker-Gill-Solovay theorem in 1975. An extremely common and powerful technique in complexity theory is to imagine a computer with a black box function called an Oracle, capable of solving a particular type of problem with a particular time complexity, but otherwise saying nothing about how it works and little about what other capabilities the computer might have. Techniques such as diagonalization can then be applied to create contradictions that prove that some types of oracles simply cannot exist.
This is the basic mechanism behind Gödel’s Incompleteness Theorems, Turing’s proof of the Undecidability of the Halting Problem, and the Time Hierarchy Theorem which allows us to prove basic things such as that running a computer for longer allows it to solve a wider range of problems.
Relativization is very effective for taking two hypothetical computers that differ in terms of their amount of some easily measurable and linearizable property, such as the amount of memory they have or the amount of time they’re allowed to run for, and to prove from this alone that the one with more can do things that the one with less cannot. Turing’s proof about undecidability for example merely shows that there exist problems that a computer can’t answer about itself, and where a more powerful computer is needed to answer them, but then showing that this still applies to a hypothetical infinitely powerful computer.
The BGS theorem showed however that relativization is useless against the P vs NP problem, and that it is possible to create one oracle that implies that P=NP, and another that implies that P!=NP. Because relativization cares so little about the details of how an oracle works, or whether different oracles are compatible with each other, it cannot answer this question.
The second barrier, the Natural Proofs Barrier, came in 1993 from Alexander Razborov and Steven Rudich. To simplify heavily, it proves that the existence of something called a One-Way-Function must imply that there cannot be any one linear property, for example “bit variance”, that we can measure for a problem that cleanly separates P and NP. There is no property like “bit variance” such that all problems in NP have “high variance”, and that circuits in P can only describe “low variance” problems. While not yet formally proven to exist, a proof that One-Way-Functions cannot exist is generally believed to be less likely than a proof that P != NP due to how the two problems are related.
The third barrier, the Algebraization Barrier, was proven in 2008 by Scott Aaronson and Avi Wigderson. This paper takes a non-relativizing technique that had been developed in response to BGS and had proven very successful in proving that the IP and PSPACE complexity classes are equivalent, and demonstrating that it too is utterly useless against the P vs NP problem.
One interpretation of BGS is that there may be alternative computing universes in some sense; the properties of computation that are logically consistent with relativization-based techniques are logically independent from those which determine whether or not NP problems are truly hard.
The Natural Proofs barrier seems to echo the difficulty in finding a definition of a “real world/easy SAT problem” that doesn’t have contradictions. Contrary to our current intuition, there may in fact not be any way to reduce complexity itself down to a single, meaningful factor.
I’m not deeply familiar with Algebraization yet to comment much on the implications of the third barrier, but needless to say it suggests that the tactics we usually use to get around these kinds of limitations are not guaranteed to work.
I wonder when we’ll see a fourth barrier. The average gap between the existing ones has been 16.5 years, so maybe we can expect the next one to be found around 2024 or 2025?
Playfair’s Axiom and Circuit Complexity
It’s often possible in mathematics to swap one axiom out for another that really just says the same thing. I often like to think of this with a linear algebra analogy, that axioms are like basis vectors that are linearly independent. You can swap out one basis vector for a different one so long as the new one is independent of the rest, and retains an equivalent span.
In the case of axioms, mathematicians call this logical independence.
One particular substitute for Euclid’s fifth postulate that I like is Playfair’s axiom, which we can even use to categorize the different geometries.
Given a line and a point not on that line, how many infinitely long lines can be drawn that pass through the point, but never through the line?

If the answer is zero, you have spherical geometry. If the answer is one, you have Euclidean geometry. If the answer is greater than one, or perhaps even infinite, you have Hyperbolic geometry. Hyperbolic even has multiple different types of parallel lines; Limiting Parallels and Ultraparallels.

Say we have an AND gate. If we know both inputs A and B, there is only one possible state that the output X can be in. However, if we take a nondeterministic approach and ask about the inputs given a value of X, we get an interesting effect.
If X is 1, then A and B are both equal to 1. We can determine this case perfectly.
However if X is 0, then AB could be 00, 01, or 10. Here there are three possible states.
Perhaps we can claim that this is because we are only providing one known value, X, and that if we know the values of two wires we can reconstruct the third. Except no, because if we know that X and A are both 0, an AND gate gives us no way of knowing whether B is 0 or 1.
We can view logic gates in terms of constructions like that used in Playfair’s axiom, where we have a combination of known and unknown values and are asking about the number of solutions to a certain constraint. In a Polynomial circuit, we can efficiently compute the outputs of each gate from its inputs and never need to deal with any uncertainty or ambiguity. This is not true in an NP circuit.
In a sense, NP seems to have something in common with Hyperbolic geometry from this perspective; a situation where other geometries provide zero ambiguity has many different options in hyperbolic scenarios.
Another peculiar property here is that if you measure the volume of these different geometries, or more specifically how the volume of a circle/sphere/hypersphere embedded in the space grows as a function of its radius, which in a sense is a measure of the number of possible states any given point could be in within that radius, we notice an interesting pattern:
Spherical geometries grow as a polynomial function until leveling off at a finite value.
Euclidean geometries grow as some unbounded polynomial function with a degree equal to the number of dimensions.
Hyperbolic geometries grow exponentially.
The Future
I have no idea if the P vs NP problem will be solved anytime soon. Maybe it’ll be solved tomorrow, maybe in another 2000 years.
However, I suspect that the ancient Greek concept of geometry being the foundation of all other mathematics perhaps may have more truth to it than we currently realize.
One last thing I’ll point out to wrap this up is that SAT problems are often pretty composable; it’s pretty easy to take two different problems, even when the two have very different difficulty levels, and bolt them together into a bigger SAT problem. We can also go in the opposite direction, breaking big problems into smaller ones with varying levels of complexity. Those combined problems will of course interact in ways that breaking them apart will obfuscate, but a lot is often still preserved.
Computer science is also a pretty bizarre field that in many ways shows little resemblence to many other fields of math. Then again, every so often you get hints of a connection back to more conventional mathematics such as the shocking effectiveness of topology in data science, or the high-dimensional geometry that has given us error correcting codes.
In the same way that Riemannian Geometry created a unified model of geometry that can model the three main types of geometries, as well as curved spaces that vary in their curvature and geometry, perhaps there is some Riemannian Complexity Theory waiting to be discovered that finally puts the P vs NP problem to rest. And perhaps there will be some patent clerk somewhere who revolutionizes our understanding of the world with it.



These are some visualizations of a certain structure inside SAT problems that I’ve found, though that I’ve left out of the discussion in this article. They’re not really a great way to visualize the particular structure I was trying to highlight, but I’m too busy right now to make better visualizations at the moment, and these are kinda pretty in their own way.
Sorry about the slight delay on this article, it was a bit longer and more involved to write than usual.
I put a lot of work and thought into this one, I hope you enjoyed it. I’ve had a few people tell me they’ve been looking forward to my covering of this subject.
I plan on doing more articles on NP and SAT in the future. If you’d like to support my writing and see more on this subject, consider sharing this article and dropping a paid subscription.