The Next Century of Computing
80 Brief Predictions for the Future

In this article, I will be giving 80 brief predictions on the future of computing and its impact on the broader world. These are largely predictions that you will not find elsewhere, and this is certainly not an exhaustive list of my ideas. However, from much of my theoretical research and various trends I’ve seen playing out, these are the places where I see things eventually deviating from common expectations.
Many of these take the form of a niche that I see existing now or in the future. How fast these predictions come true will be highly dependent on how fast people can find these niches and begin to fill them. In some ways this is a guide for people who may be interested in building a future that I hope you’ll agree with me is more interesting and inspiring than many current visions of the future.
This is not the place for me to justify these predictions with lengthy explanations of course. Such explanations may be fleshed out in future articles.
Let us start by getting the obvious out of the way. Moore’s law is coming to an end. It is slowing down rather than coming to a grinding halt, but already Dennard scaling has broken down, which eliminates many of the real benefits from scaling further for chips that are not almost entirely memory.
The end of Moore’s Law will quickly result in much more bizarre hardware. The decades ahead of us will be a Cambrian Explosion of bizarre hardware.
Existing architectures will be abandoned. No more x86, ARM, or RISC-V. However, this will go far deeper than people expect. The basic concept of computing as a machine executing a stream of instructions, shuffling data back and forth between processor and memory, will eventually be abandoned in favor of more exotic models. The models we have today will be shown to be largely arbitrary, holding back potential efficiency gains and theoretical insights with models that reflect naive computational theory from the 1940s and 50s that has yet to die far more than any fundamental nature of computing.
Legacy code will still be runnable through emulation. Native hardware support will be abandoned. Modern hardware already spends >99.9% of its complexity and energy on smoke and mirrors to provide the illusion of being an impossibly fast PDP-11. Fancy features like Out-of-Order execution, cache coherency, etc. will be scrapped and will be replaced by simpler, more efficient, more scalable hardware.
General-purpose processors will get multiple orders of magnitude faster even after the end of Moore’s law, but only by exploiting a tradeoff between performance and familiarity.
Hardware will begin to conform less to human models and more to physics. Computers are made of real atoms, use real energy, produce real heat, occupy real space, and take real time to send bits around to different locations in that space. These are things that cannot be abstracted away without paying serious costs, and without Moore’s law providing free efficiency subsidies by other means, real efficiency gains will come from deconstructing these old models and more deeply understanding the relationship between computation and fundamental physics.
Much of the mandatory rethinking of hardware design and emulation-focused compatibility will allow old design mistakes to be corrected. For example, modern OSes are only millions of lines of code today because of arbitrary HW decisions in the 90s that produced a performance advantage for embedding driver code into the OS.
It will become practical for ordinary people to write operating systems from scratch again.Silicon compilers will become common place. In response, innovative fabs will scale up wafer-sharing services. It will soon be possible to design a custom CPU or ASIC, upload the files to TSMC’s website, pay $500 and have a batch of 10 chips delivered to your door a couple months later. Hardware engineering will become almost as commonplace as software engineering.
In the short term, the inevitable Javascript chip design frameworks will create massive security problems, baked into unchangeable silicon. Software engineers are not prepared for hardware engineering. The low costs and low volumes around shared wafer prototyping will mitigate problems somewhat, but eventually the powerful formal methods tooling that has already been used by hardware engineers for decades will be forced into the hands of a much wider audience.
The computing industry will get over its irrational fear of Turing. Undecidability is deeply misunderstood; undecideable problems must be solved, and are regularly solved by any useful static analysis tool. Undecidable problems are not incomputable (that’s a separate computability class), but rather are the computational equivalent of irrational numbers; impossible to compute exactly, but rather easy to approximate. A golden age of code analysis and formal methods will follow once this misplaced fear is gone.
As hardware becomes more physics-constrained, it will simultaneously become more bizarre but also more regular. One of the first forms this will take, a form already beginning to appear in some niche, high-performance computing paradigms, is the tiled architecture; large numbers of small, simple cores in a regular grid.
While the inner workings of individual cores might become harder to immediately understand, computing will become far more geometrically intuitive.
Tesla Dojo chip, a tiled architecture 
Adapteva’s Epiphany-V, an older tiled architecture that closely resembles Dojo, but lacked the resources and software support necessary to make it a successful product Computing on tiled architectures shares much in common with distributed systems programming, albeit with more predictability and on a much smaller scale. For physics-related reasons, computing on data is cheap, moving data around is relatively expensive.
The operating system will begin to resemble a server taking up some number of cores on the chip, system calls being replaced by a simple packet-based protocol, rather than relying on context switches. Cores dedicated to specific programs or services will minimize the need to move large amounts of data around, maintaining effectively special-purpose caches.Far more powerful software diagnostic tools will be built. Debuggers that haven’t improved in any meaningful way since the 1980s will be abandoned for tools that can stream and visualize megabytes or gigabytes of data per second. Many applications will feature a dedicated diagnostics dashboard that future debuggers will be able to access.
Garbage collection for large programs will become impractical, as it relies on many behaviors that will scale absurdly poorly with physics-constrained hardware. GC may still be practical on small scales, or for programs that make little use of hardware. Programming languages and other tools will provide better and more intuitive tools for memory management, creating a middle ground between manual and automatic memory management.
Computer memory will generally make more use of memory arenas and similar techniques. This will not just provide performance advantages when freeing memory, but will also enable easier code analysis and better control of data locality (which will be one of the most important performance factors).
Combined with the increasing relevance of the physical locality of data, the concept of “heap allocation” - mixing almost all data in a program into a large homogenous region - will give way to a paradigm where memory is divided into many dedicated regions with a defined spatial layout.More visual and intuitive tooling will make a far larger impact on the ability for normies to participate in software development than any VC-backed nocode project will ever come close to achieving. Not only this, but it will vastly improve the productivity of professional software developers.
Computer science as a mathematical field will become less introverted and will begin to intermingle with other branches of mathematics on a far deeper level. It will also begin to more closely resemble traditional mathematical fields such as geometry and statistical physics. Computer science insights will then be turned around to produce deeper insights into those fields.
A Rosetta stone between computing and many seemingly unrelated fields of mathematics and physics will be developed, creating countless revolutionary insights.Much of these insights will be seeded from attempts to reverse-engineer deep learning and the brain. The tools developed there will begin to influence tooling meant for more traditional software development, highlighting deep geometric relationships at the core of computation. This will radically change how we think about computer programming. Our existing programming paradigms and language designs are extremely unlikely to survive this transition, and computing on the other side will be almost unrecognizable to us today.
This will blend nicely with physics-constrained hardware. There are close relationships between data storage, communication latency/bandwidth, and basic geometry. These relationships will become increasingly more relevant over time.
Reverse-engineering efforts in machine learning and neuroscience will bear substantial fruit. Reverse-engineering efforts in other parts of biology will soon follow. In much the same way that physics has directly inspired an enormous deal of the most powerful modern mathematics, completely new computing paradigms will emerge from studying computational systems that were designed by gradient descent or natural selection as opposed to human engineering.
Theoretical neuroscience will provide a new paradigm of error-tolerant computation. Granted, theoretical brain models with these properties have been known of for decades, but they will become more relevant in the future.
The “Singularity” will fail to materialize. The vast power of human ingenuity will prove to not be purely the result of big brains, but rather the product of human language allowing us to stand on the shoulders of giants, giants whom themselves stand upon the shoulders of others. Yes, more powerful brains will be capable of some impressive feats, but will also be prone to making many arguments along the lines of “heavy objects fall faster than light objects” without constant real-world experimentation that is not bottlenecked by compute. Exposure to real-world entropy will become a more relevant bottleneck toward progress.
Human-level AI will materialize, though largely from theoretical neuroscience research and not deep learning. The many subtle deviations from human behavior will create machines that, though intelligent, will have severe social deficits and be utterly incapable of functioning at all in society. It will be many decades before the subtleties of human behavior are understood well enough to replicate a functional human being and the interdependencies between humans will become a sharply more apparent factor.
Neural implants such as those from Neuralink and Synchron will become available and have some interesting capabilities, and will be especially be useful in helping the disabled regain function. However, until major advances are made in software development tooling and theoretical computer science, the translation from human-style computing paradigms to the comparatively-alien computing inside the brain will dramatically slow any progress on more interesting functionality.

Neuralink brain implant In the short term, multisensory computing and sensory substitution/augmentation will become a much more effective way of providing the benefits that brain implants have the ability to provide, easily possible without an implant. Humans have a strong desire for multisensory experiences.
Sensory augmentation tools will be developed for software development. It will be possible to listen to sounds that communicate useful information about the structure and behavior of code.
Sensory augmentation and substitution tools will be further developed and may be for a time a more popular alternative for disabled people to regain functionality than invasive implants.
Various forms of non-text programming tools will be developed. Purely audio-based programming will be available for blind programmers as well as someone who may want to just code via a conversation with their computer while going for a walk. Software developers may cease to be purely desk-ridden. Haptic feedback will also likely be involved.
Haptic feedback will become more common and more advanced in devices, similar to the HD Rumble in the Nintendo Switch.
The current wave of VR will generally prove to be misguided. Optimizing for iMmErSiOn will prove to be nothing more than a meme that wastes billions of dollars. A good book is immersive. The real benefit of VR will be in significantly increasing the bandwidth of data that can be extracted from the brain and by increasing the sensory range of human-computer interaction. This lesson is likely to be one that must be learned the hard way, probably bankrupting a certain trillion-dollar tech company that is currently betting the farm on it.
AR will prove to be much more useful than VR. We evolved brains to better navigate the world around us, not to escape into a fantasy world. Any country that sees any large-scale adoption of Metaverse-style tech will face both dystopia and prompt economic ruin. VR job simulators don’t put food on the table, and don’t run the fabs to make the chips that such a technology would be impossible without in the first place.
AR on the other hand will augment many very complicacted and technical jobs and will eventually prove very economically valuable.Quantum computing will prove useful in certain domains, but will likely not break any real cryptography system. It is simply far too hard to minimize noise and errors in quantum systems, both from decoherence and from the analog nature of quantum systems.
Instead, quantum computing will be most useful as a tool for simulating other quantum systems. This will revolutionize materials science.Weird emergent quantum properties will be discovered and will eventually make their way into computing devices. Exotic quantum sensors of all kinds will hit the market.
The photolithography techniques behind modern chip manufacturing will begin to be used in many other technologies. Microfluidics, MEMS, etc., plus likely many other less obvious things. For example, the electrodes used by Neuralink are already being developed using these techniques.
At some point, some solid-state quantum phenomena will be discovered that create compelling alternatives to transistors. They will not replace transistors, but rather will result in chips that combine transistors with other devices that can perform certain complex logic functions more efficiently.
CMOS logic, which has been the standard technique for digital logic for decades, already uses a combination of multiple different types of transistors, as this produces enormous energy efficiency benefits even if it roughly doubles the complexity of circuits. Expanding the toolbox beyond just two types of transistors will complicate chip design even more, but may eventually prove to be a cost worth paying.Quantum computing will influence classical computing. While quantum algorithms may be hard to simulate on classical computers, they are still possible to simulate. Some will prove useful enough (at least on small scales) to either become common tools in their own right, or inspire new approaches to old problems.
Reversible computing will become more common than quantum computing, perhaps even commonplace. This will be partly from RC being a subset of QC with simpler physical constraints (and thus easier to engineer/mass produce), but also from the fact that RC theoretically allows for vastly improved energy efficiency.
RC does have its limitations though, and the full suite of tools used in general-purpose computing with it is not practical. It will instead serve as a form of accelerator for certain workloads.Heavier research into reversible computing, likely combined with all the other revolutions going on in the rest of computing, will eventually make their way into physics, likely vastly improving our understanding of phenomena such as entropy (which is very closely related to RC and its energy efficiency benefits).
Classical computing will face the square-cube law; surface area scales faster than volume. Core count (and thus computing power) scales with volume, while memory bandwidth and I/O scale with surface area. Computers that perform less than 10,000 operations on a single byte fetched from external memory/storage/network/etc. will quickly become bottlenecked by I/O.
Of course, thermal output also scales with surface area, but the constant factors regardless still favor computers where computing power vastly exceeds memory bandwidth; this is already a phenomena faced by modern hardware, and more exotic future hardware is likely to find more inefficiencies to clean up in compute than memory I/O.
One result of this is that superlinear algorithms with time complexities such as O(n^2), O(n^3), and O(k^n) will become much more attractive. Many algorithms traditionally considered impractical to run will be opened up.
Most notably, tools like Persistent Homology and Dimensionality Reduction will become ubiquitous, as they should be. New algorithms we can’t even dream of yet will be discovered as well.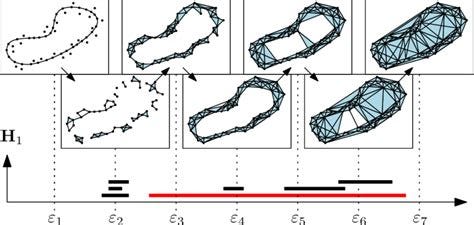
Persistent Homology can be thought of as the topological equivalent of a Fourier Transform; it takes a collection of points and extracts topological properites. This is proving to be one of the most interesting tools in modern data analysis and in reverse-engineering things like DNNs and the brain. It runs in roughly O(n^3) time. A wide range of new forms of dimensionality reduction will be developed focused on a variety of high-dimensional phenomena, not just locality. Dimensionality reduction algorithms will be combined with many other visualization techniques and become just one tool of many that can be composed into visualizations.
Common programmers will be forced to actually learn how CPU caches and similar systems work (though the on-chip memory systems of the future will be very different from those found on modern chips). One of the biggest factors for performance and efficiency of code will be the precise geometric layout of data in memory; data takes up real space, and the further away data is the more time and energy it takes to access it.
Optimizing code in this way by hand will not be practical, and more powerful code synthesis and optimization tooling will fill that role.A high compute-to-I/O ratio will also create an incentive to apply compression algorithms much more widely. You may get significant performance improvements in your code by compressing much of your data in RAM.
SAT and SMT solvers will become extremely common tools. These tools are critical for any type of formal code analysis, but also are extremely general purpose for a vast number of domains on account of these problems being NP-complete.
SAT, and by extension the entire P vs NP problem, is by far the most important open mathematical question for all of humanity right now. Nothing even comes close.
I can’t say whether the P vs NP problem will be solved any time soon, but the truly bizarre properties of NP-complete problems are extremely deeply related to pretty much every problem known to modern mathematics, and are very poorly understood. Further research into this subject will accelerate over the coming decades due to their astonishing utility and wide applicability, but also due to the extremely memory-bound hardware of the future being perfectly suited toward the worst-case exponential complexity of such algorithms.Deeper research into P v NP will result in a far deeper and clearer understanding of exactly what is and is not possible in cryptography.
Deeper research into P v NP will result in a far deeper and clearer understanding of exactly what is and is not possible in machine learning, and the nature of intelligence itself.
Existing SAT solvers are vastly more efficient than they have any theoretical reason to be. Despite being theoretically an O(2^n) problem, many real-world SAT problems with hundreds of thousands or even millions of parameters are practical to solve while many much smaller problems with only hundreds of parameters would require billions of years to solve.
However, exactly what constitutes a ”real world” problem currently is very poorly understood. This bizarrely better performance across a wide range of mysterious yet common cases suggests there are perhaps many computational shortcuts to problems that we don’t yet understand. A deeper understanding of the mathematics of SAT solvers will create a vast diversity of new computational techniques.Many bizarre properties of SAT solvers seem to strongly hint that there is something deeply, fundamentally wrong about our current understanding of computational complexity. Some deep insights are likely to shake up this understanding. I wouldn’t be surprised if we eventually drop big-O notation for a different, more powerful model of computational complexity.
Due to the fact that computationally finding chemical equillibria is at a minimum NP-complete, it seems likely that a deeper understanding of SAT solvers will also revolutionize our understanding of biology and the computing that goes on inside cells, likely revealing that many of these bizarrely powerful computing techniques we currently fail to explain in SAT solvers are the bread and butter of biological systems.
All of the bizarre new computing paradigms will create a feedback loop with tool development; a deeper understanding of computing will enable new types of tools, and new tools will make new paradigms of computing practical.
The “black box” approach to machine learning, etc. will end. The profound laziness of modern ML that creates vast AI models with minimal effort into reverse-engineering them will be looked back on as a mistake.
Superoptimization will become the dominant form of code optimization, fueled by advancements in theoretical CS that allow more intelligent navigation of such search spaces, combined with the previously-mentioned abundance of computing power relative to memory, making exponential searches much less scary to programmers.
Software development tooling based on code synthesis, or at a minimum tool-assisted fine-tuning, will become common-place. It may become commonplace for code to include a block of precise constants generated by a tool.
ML will make all non-cryptographic data easily forged. Better software tooling and a deeper understanding of P v NP will accelerate this to an extent we cannot currently imagine. Already gone are the days of “pics or it didn’t happen”.
The only real defense against powerful and dangerous ML tech will be cryptography, which luckily, will also get profoundly more powerful.
The rest of this article is behind a paywall. Past here is another 25 predictions regarding machine learning, crypto, industry, and broader social impacts of technology.




Keep reading with a 7-day free trial
Subscribe to Bzogramming to keep reading this post and get 7 days of free access to the full post archives.